Dealing with False Ping Alerts in LogicMonitor: Building a Fallback Ping Monitoring Script for Production VMs
Problem Statement
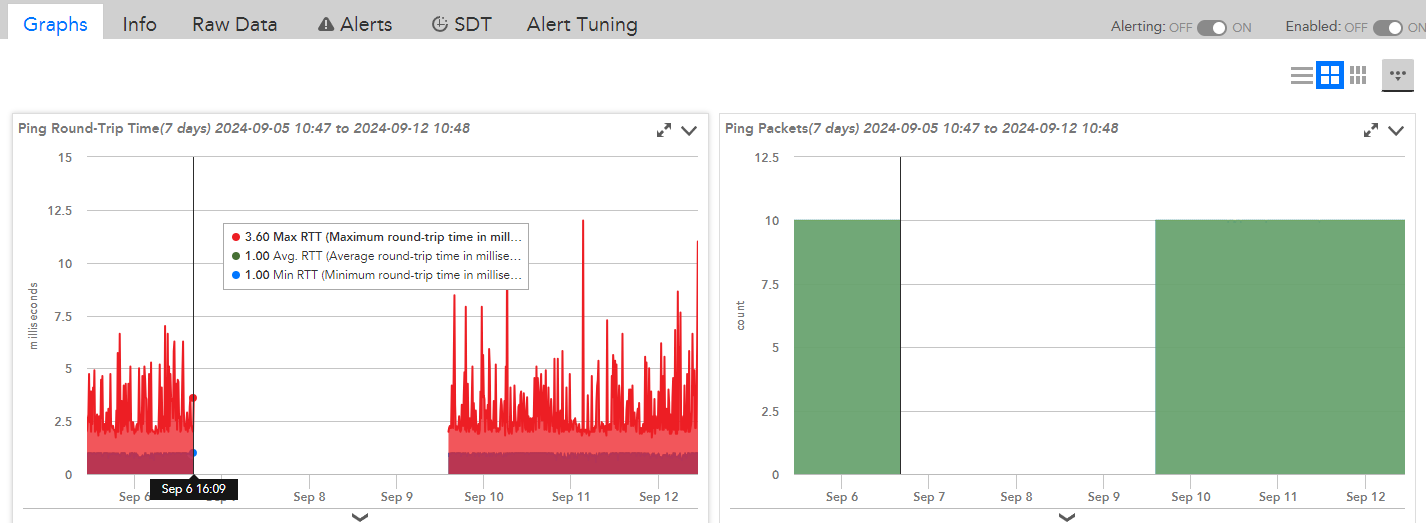
On Friday 6th September 2024 at 21:31, we received an alert from LogicMonitor indicating one of our production web app servers (Tomcat#3) was down, with the message: "The host Tomcat#3 (i-xxxxxxx) is down". However, shortly after receiving the alert, we attempted to SSH into the VM and confirmed that the server was fully operational.
Root Cause Investigation and Resolution
A ticket was promptly raised with our IT service provider, responsible for managing our Cloud Production workloads, immediately following the alert. Their investigation provided the following findings:
- 1. Ping Data: Ping data from the server stopped reporting at 16:09 on the same day.
- 2. Other Metrics: All other performance metrics from the server were reported normally, indicating that the server was functioning properly aside from the ping data issue.
- 3. Environment Consistency: Other servers in the same environment (e.g., Tomcat#1) continued to report ping data normally, indicating that the issue was isolated to Tomcat#3.
Upon further analysis by our service provider, it was determined that the ping data had stopped reporting at 16:09, resulting in a delayed false alert at 21:31. The root cause of the issue was traced to a malfunction in the service provider’s monitoring tool, which failed to capture ping data properly. Once the issue with the monitoring tool’s collector was resolved on Monday, September 9th, ping monitoring resumed, and the false alert was cleared.
Graph Explanation
The graph below shows that the ping metrics, including round-trip time and packet counts, were being reported normally up until 16:09 on September 6th. After that, no new ping data was collected, confirming the issue was related to the monitoring service rather than the server itself.
In-House Alternative Solution: Fallback Ping Monitoring Script
To reduce reliance on third-party monitoring services, I created a fallback ping monitoring script. Running on a separate VM, it pings target servers and sends email alerts if they don’t respond after several attempts. It’s a simple fallback solution for basic connectivity checks.
Environment setup:
This fallback ping monitoring solution was implemented and tested in an AWS environment. The setup included 3 EC2 instances:
- 1 EC2 instance acting as the
ping-monitoring server(our VM, not a service provider’s monitoring system). - 2 EC2 instance as the
target hosts.
Implementation steps
Steps 1 through 3 are the prerequisites before running the ping-failure-alert.sh script on our dedicated VM, which is acting as the monitoring server (not the service provider’s monitoring system).
Step 1 - Allow ICMP Through the Firewall
- Monitoring Server (our VM): Allow outbound ICMP traffic (ping) for all destinations.
- Target Servers: Allow inbound ICMP from the monitoring server’s IP.
- Test Connectivity: Run ping
<target_host_public_IP>from the monitoring server to ensure reachability.
Step 2 - Install mailx package to enable email notification
mailx is a command-line email client used in Unix-like systems to send and receive emails directly from the terminal or within scripts.
- For Debian/Ubuntu:
sudo apt-get install mailx - For RHEL/CentOS:
sudo yum install mailx - For Fedora:
sudo dnf install mailx
Step 3 - Gmail Configuration for SMTP Authentication
To ensure that the script can send email notifications using Gmail’s SMTP service, you need to configure Gmail accordingly. Follow these steps:
- Enable App Passwords in Gmail if Two-Step Verification is on.
- Create an
App PasswordunderGoogle Account > Security > App Passwords. - Update
/etc/mail.rcon the Monitoring server with the following configuration:
set smtp=smtps://smtp.gmail.com:465
set smtp-auth=login
set smtp-auth-user=<your_email_id>@gmail.com # provide the main Gmail address
set smtp-auth-password=<your_generated_app_password> # do not leave any spaces between characters
set ssl-verify=ignore
Step 4 - Ping Monitoring Script
The bash script below pings the servers and sends alerts via email if they are unreachable.
- Create the script file and open it for editing (
sudo nano ping-failure-alert.sh). - Ensure the script is executable (
sudo chmod +x ping-failure-alert.sh). - Restrict access to root only for security (
sudo chown root:root ping-failure-alert.shandsudo chmod 700 ping-failure-alert.sh).
#################################################################################
# Script Name: ping-failure-alert.sh
# Description: This script pings a predefined list of server IP addresses to check
# their network connectivity. If any servers fail to respond after
# a specified number of attempts and interval, an email notification
# is sent.
# Author: Mickael Asghar
# Created on: 07/06/2024
# Updated on: 07/06/2024
#################################################################################
#!/bin/bash
# Email Configuration - Define email addresses here
recipient_email="ping-monitoring@abc.com" # Define the primary recipient
cc_recipients=("contact1@abc.com" "contact2@abc.com) # Define CC recipients
# Convert CC recipients array to a comma-separated string
cc_list=$(IFS=','; echo "${cc_recipients[*]}")
# Associative array of server IP addresses and their hostnames
declare -A ping_targets=(
["10.15.30.40"]="target_host_1" # adjust IP address and hostname
["50.60.70.80"]="target_host_2" # adjust IP address and hostname
["90.95.100.110"]="target_host_3" # adjust IP address and hostname
)
# Retry settings
retry_count=3 # Number of retry attempts
retry_interval=30 # Interval in seconds between retries
# Initialize a variable to store failed hosts
failed_hosts=""
# Function to ping a host
ping_host() {
local ip=$1
ping -c 1 $ip > /dev/null 2>&1
return $?
}
# Loop through each target and attempt to ping
for ip in "${!ping_targets[@]}" # Loop over keys of the associative array
do
hostname=${ping_targets[$ip]} # Assign hostname from the associative array
success=false
for attempt in $(seq 1 $retry_count)
do
echo "Pinging $hostname ($ip) (Attempt $attempt of $retry_count)..."
if ping_host $ip; then
echo "$hostname ($ip) is reachable."
success=true
break
else
echo "$hostname ($ip) is not reachable. Waiting $retry_interval seconds before retrying..."
sleep $retry_interval
fi
done
if ! $success; then
current_datetime=$(date "+%d/%m/%Y %H:%M:%S") # Get the current date and time
echo "$hostname ($ip) failed to respond after $retry_count attempts."
failed_hosts+="Date: $current_datetime - $hostname ($ip).\n" # Append formatted string
fi
done
# Check if any host failed to respond and send an email if so
if [ ! -z "$failed_hosts" ]; then
message="The following hosts failed to respond after $retry_count attempts with a $retry_interval second interval between attempts:\n$failed_hosts"
echo -e "$message" | mailx -s "[ALERT] - Ping Failure Notification" -c "$cc_list" "$recipient_email"
else
echo "All hosts responded successfully after $retry_count attempts."
fi
Key Settings:
- Retry Attempts (retry_count): The script will try to ping each server 3 times before declaring it unreachable.
- Interval Between Retries (retry_interval): There is a 30-second interval between retries. This ensures that short downtimes (e.g., server reboot) will not trigger immediate false alerts.
- Adjust values accordingly to meet your requirements:
recipient_email,cc_recipients,target_host_IP,target_hostname
Step 5 - Set up the Script as a Cron Job
To automate the script, run it as a cron job every 5 minutes:
- Open Crontab:
sudo crontab -e - Add the Cron Job:
*/5 * * * * /path/to/ping-failure-alert.sh
- Replace
/path/to/ping-failure-alert.shwith the actual path to your script.
Avoiding Unnecessary Alerts
With 3 retry attempts and a 30-second interval, the script waits ~90 seconds before declaring a server unreachable. This reduces unnecessary alerts for brief downtimes, like reboots.
Conclusion
The false alert caused by the monitoring collector led us to realize that the server was never down, despite the loss of ping data. Having a fallback ping monitoring script offers a reliable alternative for connectivity checks, ensuring you’re not misled by false positives from external services. This backup system is lightweight, customisable, and independent of the main monitoring service.